IRQBalance: How It Works - Comprehensive Analysis
Written on March 8th, 2026 by Mukesh Kumar Chaurasiya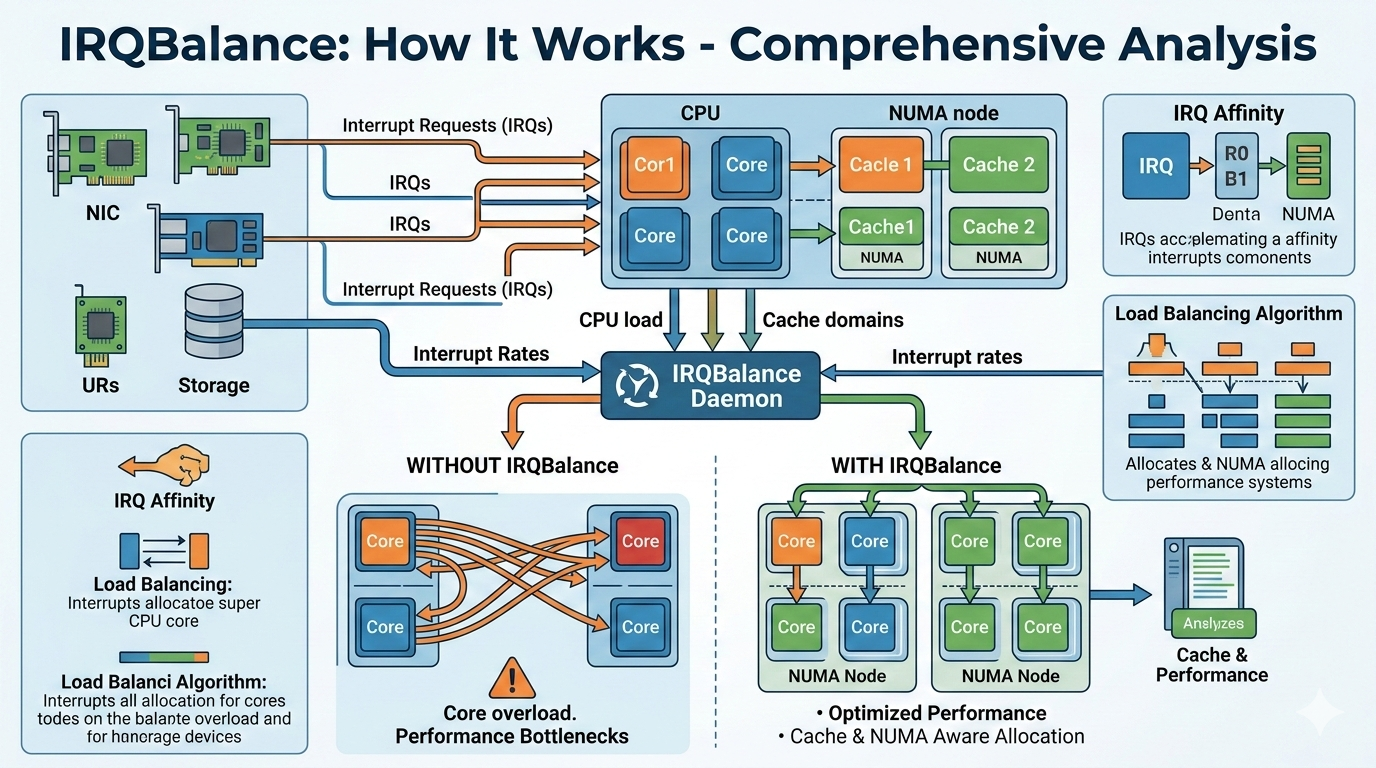
IRQBalance: How It Works - Comprehensive Analysis
Overview
IRQBalance is a daemon that distributes hardware interrupt load across CPUs to optimize performance while minimizing cache misses. It runs periodically (default: 10 seconds) to analyze interrupt patterns and adjust CPU affinity.
Core Architecture
1. Hierarchical CPU Topology
IRQBalance builds a tree structure representing the system:
NUMA Nodes (top level)
└─> CPU Packages (sockets)
└─> Cache Domains (shared L2/L3 cache)
└─> CPU Cores (individual CPUs)
2. How IRQBalance Hints Hardware for CPU Selection
The mechanism is NOT direct hardware hinting - it’s kernel-level affinity control:
- Writes to
/proc/irq/<irq_num>/smp_affinity- IRQBalance writes a CPU bitmask to this file
- The Linux kernel reads this and programs the interrupt controller
- Hardware then routes interrupts to CPUs in the specified mask
-
CPU Selection Decision Process:
Step 1: Load Calculation
- Calculates load statistics for each hierarchy level
- Computes average load and standard deviation
- Identifies overloaded and underloaded objects
Step 2: Migration Threshold
if (migrate_ratio > 0) { delta_load = (adjustment_load - min_load) / migrate_ratio; }- Only migrates if:
(min_load + irq_load) < delta_load + (adjustment_load - irq_load) - This prevents “ping-pong” migrations
Step 3: Placement Algorithm
- Finds object with lowest load (
best_cost) - Checks if object has available slots (
slots_left > 0) - Skips objects in powersave mode
- Considers banned CPUs (isolated/nohz_full)
3. Cache Awareness - YES, It Does Consider Cache!
Cache is a PRIMARY consideration in the design:
Cache Domain Hierarchy
cache_domains // Represents CPUs sharing L2/L3 cache
Three-Level Balancing Strategy:
- BALANCE_PACKAGE
- IRQs balanced across CPU packages
- Used for low-priority interrupts (IRQ_OTHER)
- BALANCE_CACHE
- IRQs balanced within cache domains
- Minimizes cache misses by keeping related interrupts on CPUs sharing cache
- Used for most device classes
- BALANCE_CORE
- IRQs pinned to specific cores
- Used for high-performance devices (10GbE, storage)
Cache-Aware Placement
for_each_object(numa_nodes, place_irq_in_object, NULL);
for_each_object(packages, place_irq_in_object, NULL);
for_each_object(cache_domains, place_irq_in_object, NULL); // Cache level!
The algorithm places IRQs hierarchically, ensuring:
- IRQs stay within their cache domain when possible
- Cache coherency is maintained
- Related interrupts share cache lines
4. CPU Load Thresholds for Migration
Load-Based Migration
When does it select a new CPU?
- Standard Deviation Threshold:
if ((obj->load - std_deviation) >= avg_load) // Overloaded if ((obj->load + std_deviation) <= avg_load) // Underloaded - Minimum Requirements:
- Object must have > 1 IRQ
- IRQ load must be > 1
- Object load must exceed minimum load
- Migration Ratio Control:
- Configurable via
--migratevalor-eoption - Default: 0 (migrate if beneficial)
- Higher values = more conservative migration
- Configurable via
Power Management Integration
if (power_thresh != ULONG_MAX && cycle_count > 5) {
if (!num_over && (num_under >= power_thresh) && powersave) {
powersave->powersave_mode = 1; // Enter powersave
}
}
5. Key Configuration Parameters
--deepestcache(-c): Cache level to balance at (default: 2 = L2/L3)--migrateval(-e): Migration aggressiveness ratio--powerthresh(-p): CPUs needed underloaded before powersave--interval(-t): Scan interval in seconds (default: 10)
6. Hardware Interaction Flow
1. Parse /proc/interrupts → Count IRQs per CPU
2. Calculate load per IRQ (irq_count - last_irq_count)
3. Aggregate load up hierarchy (CPU → Cache → Package → NUMA)
4. Identify imbalanced objects (std_deviation analysis)
5. Select IRQs for migration (move_candidate_irqs)
6. Calculate best placement (find_best_object)
7. Write to /proc/irq/N/smp_affinity → Kernel updates APIC/GIC
8. Hardware routes future interrupts to new CPU(s)
IRQ Affinity Write Path (irqbalance → kernel)
1. User Space (irqbalance) writes to:
/proc/irq/<irq_num>/smp_affinity(hex format)/proc/irq/<irq_num>/smp_affinity_list(list format)
2. Kernel Entry Point (kernel/irq/proc.c):
write_irq_affinity()→irq_set_affinity()
3. Generic IRQ Layer (kernel/irq/manage.c):
irq_set_affinity()→__irq_set_affinity()irq_set_affinity_locked()→irq_try_set_affinity()irq_do_set_affinity()→ callschip->irq_set_affinity()
4. XIVE IRQ Chip Handler (arch/powerpc/sysdev/xive/common.c):
xive_irq_set_affinity():- Validates the new CPU mask
- Picks a target CPU using
xive_pick_irq_target() - Calls
xive_ops->configure_irq()with:- Hardware IRQ number
- Physical CPU ID via
get_hard_smp_processor_id(target) - Priority
- Linux IRQ number
XIVE Programming (Hardware Configuration)
For SPAPR (PowerVM/LPAR) - Hypervisor Call:
xive_spapr_configure_irq()(arch/powerpc/sysdev/xive/spapr.c, line 450)- Makes
H_INT_SET_SOURCE_CONFIGhypercall - Hypervisor programs the XIVE interrupt controller
For Native/Bare Metal (PowerNV) - OPAL Call:
xive_native_configure_irq()(arch/powerpc/sysdev/xive/native.c, line 99)- Calls
opal_xive_set_irq_config() - OPAL firmware programs the XIVE hardware directly
Key Points:
- Affinity Storage: The affinity mask is stored in
desc->irq_common_data.affinity - Target Selection: XIVE tries to pick CPUs on the same chip as the interrupt source for better performance
- Hardware Programming: The actual target CPU is programmed into XIVE via either hypervisor (H_INT_SET_SOURCE_CONFIG) or OPAL (opal_xive_set_irq_config)
- Effective Affinity: Can be read from
/proc/irq/<irq>/effective_affinityto see where the IRQ is actually routed
The flow is: irqbalance → /proc/irq/N/smp_affinity → generic IRQ layer → XIVE chip driver → hypervisor/OPAL → XIVE hardware
Summary
The cache domain hierarchy ensures IRQs are placed to minimize cache misses. CPU selection happens when load imbalance exceeds statistical thresholds (standard deviation from average), with configurable migration ratios to prevent thrashing. The “hint” to hardware is actually a kernel interface (smp_affinity) that programs the interrupt controller to route interrupts to specific CPUs.